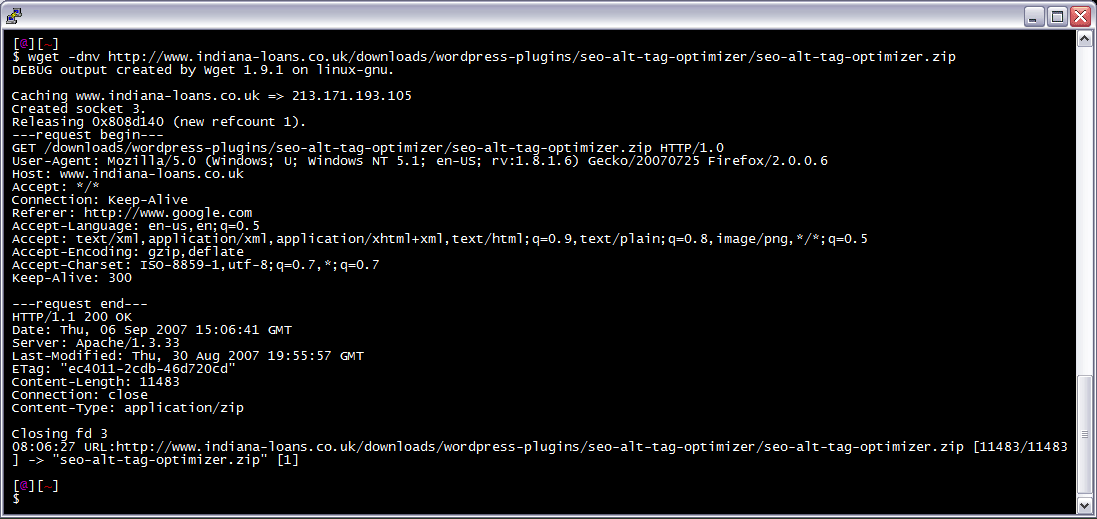
Information on bounced messages: NDR Codes
Please note, that each bounce message is different. Therefore, information relating to
addresses, IP numbers, and domain names listed below will differ from what listed in your
header information. If you have received a bounce message (NDR: Non-Delivery Report) that matches one of the
following messages, find the text that follow below for a complete description.
As you examine an NDR message, look out for a three-digit code, for example, 5.2.1.
If the first number begins with 5.y.z, then it means you are dealing with a permanent error; this message will never be delivered. Occasionally, you get NDRs beginning with 4.y.z, in which case there is hope that email will eventually get through. The place to look for the NDR status code is on the very last line of the report.
NDR codes like 5.5.0 or 4.3.1 may remind you of SMTP errors 550 and 431. Indeed, the 500 series in SMTP has a similar meaning to the 5.y.z codes in an NDR - failure. I expect that you have worked out why there are no 2.y.z NDRs? The reason is that the 2.y.z series mean success, whereas Non-Delivery Reports, by definition, are failures.
NDR Classification As you are beginning to appreciate, these status codes are not random. The first number 4.y.z, or 5.y.z refers to the class of code, for example, 5.y.z is permanent error. Incidentally, we have not seen any status codes beginning with 1.y.z, 3.y.z, or indeed any numbers greater than 5.7.z.
The second number x.1.z means subject. This second digit, 1 in the previous example, gives generic information where as the third digit (z) gives detail. Unfortunately, we have not cracked the complete code for the second digit. However, I have discovered a few useful patterns, for instance, 5.1.x indicates a problem with the email address, as apposed to server or connector problem. In addition, 5.2.x means that the email is too big, somewhere there is a message limit.
Conclusion, it is best to look up your three-digit error in the status code, see NDR table below.
[edit] Most Common Bounce Reasons
- Message rejected: The mailserver used does not match the domain specified
- 450: Recipient address rejected: Domain not found
- 450: unknown[10.123.123.123] : Client host rejected: Too many mails sent!; from=emaillist@domain.com
- 500: Recipient address rejected: Recipient mailbox is full
- 503: Improper use of SMTP command pipelining
- 540: email@domain.com : Recipient address rejected: Your email has been returned because the intended recipient's email account has been suspended.
- 550: abcdefghijk@excite.com: User unknown
- 550: name.mail.domain.net[10.x.xxx.xx]: Client host rejected: More than X concurrent connections per subnet
- 554: unknown[10.xxx.xxx.xx]: Client host rejected: Access denied
- 554: Client host rejected: cannot find your hostname, [10.xxx.xx.xxx]; from=xxxxx@hotmail.com
- 554: Sender address rejected: Access denied
- 554: Service unavailable; [10.xxx.xx.xxx] blocked using relays.ordb.org, reason: This mail was handled by an open relay - please visit http://ORDB.org/lookup/?host=10.X.X.X
- 554: Relay access denied; from=<email@domain.com> to=<email@anotherdomain.com> - reject: header Subject: (Email Subject Line)
- Remote host said: 554 Service unavailable; [XXX.XXX.XXX.XXX] blocked using blackholes.excite.com
[edit] Explanation of various bounce messages
[edit] Message rejected
The mailserver used does not match the domain specified</b>
This message was not delivered because the headers indicate that it is coming from an email service other than the one indicated by the IP address. It is a common practice of Spammers to forge message headers in this manner, therefore this type of message will not be delivered.
For example, a message with a return address of 1user@domainname.com which was actually sent through a service with an IP address which does not match domainname.com will be rejected for this reason.
[edit] 450: Recipient address rejected: Domain not found
450 unknown[10.123.123.123]: Client host rejected: Too many mails sent!; from=emaillist@domain.com</b>
To protect email system from being flooded by email list administrators, or in some cases by "spammers," ISP's have instituted "rules" to gate incoming email to their systems.
These rules are mostly based on common industry practices as to how to send large amounts of email without causing potential harm to the recipient's mail server.
Unfortunately, from time to time, we are forced to "soft bounce messages because the mailing it was a part of exceeded one or more of the rules for incoming email. However, a "soft bounce" means that we will deliver the email in question, although it will result in a short delay in receipt.
The mail servers that were responsible for delivering the bounced message may have been blocked due to a high number of concurrent connections. This type of abuse is usually indicative of a "spammer" trying to send unsolicited commercial emails. Therefore, the message was blocked along with all other messages from that mail server. This decision is made automatically by computer programs and do result in a significant percentage of false positives. Since the email provider in question has been added to one or more block list(s), the bounced message will continue to be generated.
[edit] 500: Recipient address rejected: Recipient mailbox is full
The email address in question is over its storage limit. For example:
- Excite mail accounts are currently set up with 125MBs of storage space, or 10,000 emails.
- The storage limit for a free Yahoo! Mail account is 1GB.
-
When an email account goes over the quota, emails sent to that account will be
"bounced" back to the sender until the space has been cleared. Unfortunately, we have no
way of knowing if the member in question is aware of the status of their storage space, or
the frequency with which they check their quota.
At ACOR, since many of our subscribers go away for treatment for long periods of time, we receive a lot of those error messages.
[edit] 503: Improper use of SMTP command pipelining
The message was sent in a non-conventional, non-standard way. You should have the
sender of this email contact us if they have further questions.
[edit] 540: < email@domain.com >: Recipient address rejected
Your email has been returned because the intended recipient's email account has been suspended. The account must be
re-activated to receive incoming messages.</b>
As noted often in the Free Email Services Terms of Service, email accounts that have not been accessed
for more than xxxx days may be deactivated.
If you are an Excite Member, you can reactivate your account by simply signing in to your
Email account, where you will be prompted with a message asking if you would like to
reactivate your email account. After agreeing to do so, your email address will automatically
be reactivated. Please note it may take up to two hours for you to begin receiving new
email messages after you've reactivated the account, and remember to access your email
at least once every 60 days to prevent this from occurring in the future.
If you received a "bounced" message to one of the Free Email Services Providers email
user, we suggest that you find an alternate mean of communicating with them to let them
know their email account is now inactive, and that they need to access their Inbox
to reactive their email account.
[edit] 550: abcdefghijk@excite.com: User unknown
If the Excite email account in question is generating "bounced" message that state "User
Unknown" when an individual attempts to send email to it, it could mean that the email
account was not activated after the user registered for their Excite Member account.
For the Excite email account to have been activated, the Member would need to have been
signed into their Excite Member account. From there, they would have been prompted to
agree with the Excite email system's Terms of Service and Privacy Policy by selecting the
"Accept and Continue" option. Once this was complete, the Member would need to have
signed into the Excite email account to fully activate it. Furthermore, the account will not
start receiving email until 1 hour after it has been fully activated.
If you are sure that the Excite email account in question has been fully activated, and the
account in question is still generating "User Unknown" bounced messages, please contact
your email administrator, and ask them to contact us at emailadmin@cs.excite.com for
further assistance.
550: name.mail.domain.net[10.x.xxx.xx]: Client host rejected: More than 20 concurrent connections per subnet
It appears that the mail servers that were responsible for delivering the message to us were
temporarily blocked due to a high number of concurrent connections. This type of abuse is
usually indicative of a "spammer" trying to send unsolicited commercial emails. Therefore,
the message was blocked along with all other messages from that mail server at that time.
However, it is likely that the block was subsequently removed.
554: unknown[10.xxx.xxx.xx]: Client host rejected: Access denied
554: Sender address rejected: Access denied
Your message is being blocked by our site because it either had characteristics similar to
"spam" (unsolicited commercial email), or you're sending your message from an Internet
Service Provider (ISP) or email provider who has been identified as having allowed spam to
be generated from their facilities. For the protection of our members, we do not deliver
bulk, unsolicited emails to Excite email accounts.
For example, it is possible that the subject line of the message in question may have been
identified by our email servers as unsolicited commercial mail (AKA: Spam) and thus was
returned. We ask that you retry sending your message with a different subject line. Please
ensure that the subject line of the message does not contain more than 15 identical
characters.
For instance, if a subject line contains 15 identical consecutive characters, such as 15 "a"s
or 15 "!"s it may be rejected on our end.
However, if your ISP or email provider has been added to our block list, your email message
to @excite.com will continue to be rejected or a bounced message will continue to be
generated. If this is the case, please contact your email administrator, and ask them to
contact us for further assistance.
554: Sender address rejected: Access denied
- This address is listed on our "black list" of email addresses, or is on the black list of one of
the spam filter lists we use to lessen the amount of Spam our users receive. You should
have the owner of this address contact us if they have questions.
554: Service unavailable; [10.xxx.xx.xxx] blocked using relays.ordb.org, reason: This mail was handled by an open relay - please visit http://ORDB.org/lookup/?host=10.X.X.X
The message in question was blocked because it came from a domain or IP address that is
currently listed with one of our Spam filters. These filters are utilized to help prevent
excessive spamming to our email providers. If your domain or IP address is listed with any
of the four Spam filters we currently use, your message will not be delivered.
If you believe that you have been unfairly added to any or all of these particular lists,
please contact the website in question:
- Ordb (relays.ordb.org)
- Spamcop (bl.spamcop.net)
- Osirusoft (socks.relays.osirusoft.com)
- Wirehub (blackholes.wirehub.net)
- Spamhaus
554: Client host rejected: cannot find your hostname, [10.xxx.xx.xxx]; from=xxxxx@hotmail.com
554: Relay access denied; from=email@domain.com to=email@anotherdomain.com
This error means that the person sending the email was not authorized to use the email
server (SMTP) server to send email. They should contact their ISP or email provider.
reject: header Subject: (Email Subject Line Here)
This subject line is on our "black list" of subject lines, or is on the black list of one of the
spam filter lists we use to lessen the amount of Spam our users receive. You should have
the sender of this email contact us if they have questions, or ask them, to change the
subject line, which unfortunately appears to have been used as the subject of a "spam" message at some time.
Remote host said: 554 Service unavailable; [XXX.XXX.XXX.XXX] blocked using blackholes.excite.com
We have recently received a large number of abuse complaints regarding your account (and/or your ISP). As a result, we have bounced your email message back to you.
This means your IP number (represented above by XXX.XXX.XXX.XXX) has been blocked due to spamming activity by you, or someone using the same IP address or IP address range from your ISP. You may wish to let your ISP know of the situation. While this blocks are usually temporary, if we see repeated activity from this IP address or IP address range, it may be permanently blocked from sending email to our mail system
We hope this answers your questions about bounced email to our mail system.
Standard SMTP Reply Codes:
| Code | Description |
| 211 | System status, or system help reply. |
| 214 | Help message. |
| 220 | Domain service ready.
Ready to start TLS. |
| 221 | Domain service closing transmission channel. |
| 250 | OK, queuing for node node started.
Requested mail action okay, completed. |
| 251 | OK, no messages waiting for node node.
User not local, will forward to forwardpath. |
| 252 | OK, pending messages for node node started.
Cannot VRFY user (e.g., info is not local), but will take message for this user and attempt delivery. |
| 253 | OK, messages pending messages for node node started. |
| 354 | Start mail input; end with <CRLF>.<CRLF>. |
| 355 | Octet-offset is the transaction offset. |
| 421 | Domain service not available, closing transmission channel. |
| 432 | A password transition is needed. |
| 450 | Requested mail action not taken: mailbox unavailable.
ATRN request refused. |
| 451 | Requested action aborted: local error in processing.
Unable to process ATRN request now |
| 452 | Requested action not taken: insufficient system storage. |
| 453 | You have no mail. |
| 454 | TLS not available due to temporary reason.
Encryption required for requested authentication mechanism. |
| 458 | Unable to queue messages for node node. |
| 459 | Node node not allowed: reason. |
| 500 | Command not recognized: command.
Syntax error. |
| 501 | Syntax error, no parameters allowed. |
| 502 | Command not implemented. |
| 503 | Bad sequence of commands. |
| 504 | Command parameter not implemented. |
| 521 | Machine does not accept mail. |
| 530 | Must issue a STARTTLS command first.
Encryption required for requested authentication mechanism. |
| 534 | Authentication mechanism is too weak. |
| 538 | Encryption required for requested authentication mechanism. |
| 550 | Requested action not taken: mailbox unavailable. |
| 551 | User not local; please try forwardpath. |
| 552 | Requested mail action aborted: exceeded storage allocation. |
| 553 | Requested action not taken: mailbox name not allowed. |
| 554 | Transaction failed. |
| NDR Code | Explanation of Non-Delivery Report error codes from Email Servers |
| 4.2.2 | The recipient has exceeded their mailbox limit. It could also be that the delivery directory on the Virtual server has exceeded its limit. |
| 4.3.1 | Not enough disk space on the delivery server. Microsoft say this NDR maybe reported as out-of-memory error. |
| 4.3.2 | Classic temporary problem, the Administrator has frozen the queue. |
| 4.4.1 | Intermittent network connection. The server has not yet responded. Classic temporary problem. If it persists, you will also a 5.4.x status code error. |
| 4.4.2 | The server started to deliver the message but then the connection was broken. |
| 4.4.6 | Too many hops. Most likely, the message is looping. |
| 4.4.7 | Problem with a timeout. Check receiving server connectors. |
| 4.4.9 | A DNS problem. Check your smart host setting on the SMTP connector. For example, check correct SMTP format. Also, use square brackets in the IP address [197.89.1.4] You can get this same NDR error if you have been deleting routing groups. |
| 4.6.5 | Multi-language situation. Your server does not have the correct language code page installed. |
| 5.0.0 | SMTP 500 reply code means an unrecognised command. You get this NDR when you make a typing mistake when you manually try to send email via telnet.
More likely, a routing group error, no routing connector, or no suitable address space in the connector. (Try adding * in the address space)
This status code is a general error message in Exchange 2000. In fact Microsoft introduced a service pack to make sure now get a more specific code. |
| 5.1.x | Problem with email address. |
| 5.1.0 | Often seen with contacts. Check the recipient address. |
| 5.1.1 | Another problem with the recipient address. Possibly the user was moved to another server in Active Di |
Reference:
http://lo-wiki.acor.org/index.php/SMTP_Error_CodesTo download the complete pdf:
http://www.answersthatwork.com/Download_Area/ATW_Library/Networking/Network__3-SMTP_Server_Status_Codes_and_SMTP_Error_Codes.pdf